TOP命令
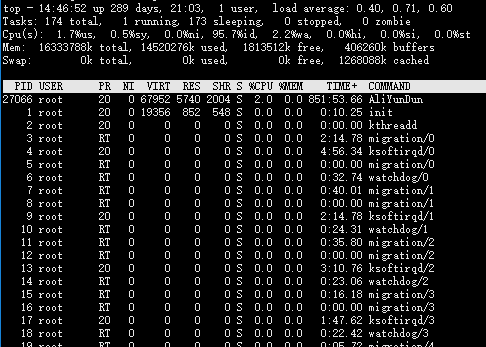
一. TOP前五行统计信息
统计信息区前五行是系统整体的统计信息。
1. 第一行是任务队列信息
同 uptime 命令的执行结果:
[root@localhost ~]# uptime
13:22:30 up 8 min, 4 users, load average: 0.14, 0.38, 0.25
其内容如下:
|
12:38:33 |
当前时间 |
|
up 50days |
系统运行时间,格式为时:分 |
|
1 user |
当前登录用户数 |
|
load average: 0.06, 0.60, 0.48 |
系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
2. 第二、三行为进程和CPU的信息
当有多个CPU时,这些内容可能会超过两行。内容如下:
|
Tasks: 29 total |
进程总数 |
|
1 running |
正在运行的进程数 |
|
28 sleeping |
睡眠的进程数 |
|
0 stopped |
停止的进程数 |
|
0 zombie |
僵尸进程数 |
|
Cpu(s): 0.3% us |
用户空间占用CPU百分比 |
|
1.0% sy |
内核空间占用CPU百分比 |
|
0.0% ni |
用户进程空间内改变过优先级的进程占用CPU百分比 |
|
98.7% id |
空闲CPU百分比 |
|
0.0% wa |
等待输入输出的CPU时间百分比 |
|
0.0% hi |
|
|
0.0% si |
3. 第四五行为内存信息。
内容如下:
|
Mem: 191272k total |
物理内存总量 |
|
173656k used |
使用的物理内存总量 |
|
17616k free |
空闲内存总量 |
|
22052k buffers |
用作内核缓存的内存量 |
|
Swap: 192772k total |
交换区总量 |
|
0k used |
使用的交换区总量 |
|
192772k free |
空闲交换区总量 |
|
123988k cached |
缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。 |
二. 进程信息
| 列名 | 含义 |
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb。 |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。 D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志,参考 sched.h |
SAR 命令
root@CentOS-7:~# sar --help
用法: sar [ 选项 ] [ <时间间隔> [ <次数> ] ]
选项:
[ -A ] [ -B ] [ -b ] [ -C ] [ -d ] [ -H ] [ -h ] [ -p ] [ -q ] [ -R ]
[ -r ] [ -S ] [ -t ] [ -u [ ALL ] ] [ -V ] [ -v ] [ -W ] [ -w ] [ -y ]
[ -I { <中断> [,...] | SUM | ALL | XALL } ] [ -P { <cpu> [,...] | ALL } ]
[ -m { <关键词> [,...] | ALL } ] [ -n { <关键词> [,...] | ALL } ]
[ -j { ID | LABEL | PATH | UUID | ... } ]
[ -f [ <文件名> ] | -o [ <文件名> ] | -[0-9]+ ]
[ -i <间隔> ] [ -s [ <时:分:秒> ] ] [ -e [ <时:分:秒> ] ]
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
cpu信息
sar -u 1

%nice:通过nice改变了进程调度优先级的进程,在用户模式下消耗的CPU时间的比例;
%system:系统模式下消耗的CPU时间的比例;
%iowait:CPU等待磁盘I/O而导致空闲状态消耗时间的比例;
%steal:利用Xen等操作系统虚拟化技术时,等待其他虚拟CPU计算占用的时间比例;
%idle:CPU没有等待磁盘I/O等的空闲状态消耗的时间比例;注:
如果 %iowait 的值过高,表示硬盘存在I/O瓶颈
如果 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
如果 %idle 的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
如果要查看二进制文件test中的内容,需键入如下sar命令:
sar -u -f test
inode、文件和其他内核表监控
sar -v 1 5

dentunusd:目录高速缓存中未被使用的条目数量
file-nr:文件句柄(file handle)的使用数量
inode-nr:索引节点句柄(inode handle)的使用数量
pty-nr:使用的pty数量
内存和交换空间监控
sar -r 1 5
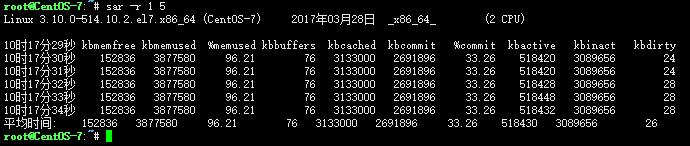
输出项说明:
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
内存分页监控
sar -B 10 3
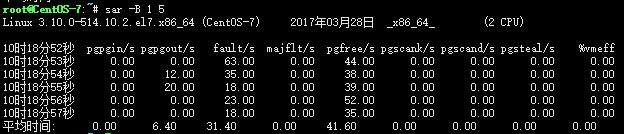
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
磁盘IO
sar -b 1 5
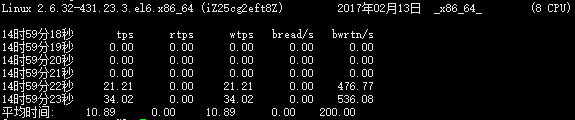
tps: 每秒钟物理设备的 I/O 传输总量
rtps: 每秒钟从物理设备读入的数据总量
wtps: 每秒钟向物理设备写入的数据总量
bread/s: 每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s: 每秒钟向物理设备写入的数据量,单位为 块/s
进程队列长度和平均负载状态监控
sar -q 1 5
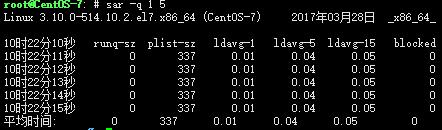
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(System load average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
系统交换活动信息监控
sar -W 1 5
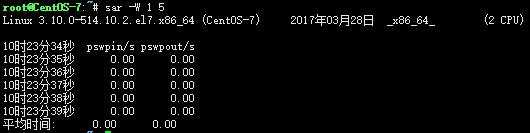
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
设备使用情况监控
sar -d 1 5 -p

参数-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度.
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和.
1. avgqu-sz 的值较低时,设备的利用率较高。
2. 当%util的值接近 1% 时,表示设备带宽已经占满。
网络信息
sar -n DEV 1

iostat命令
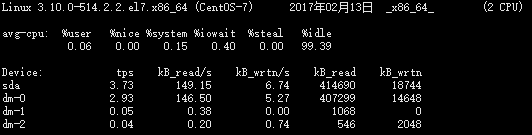
第一部分包含了CPU报告
- %user : 显示了在执行用户(应用)层时的CPU利用率
- %nice : 显示了在以nice优先级运行用户层的CPU利用率
- %system : 显示了在执行系统(内核)层时的CPU利用率
- %iowait : 显示了CPU在I/O请求挂起时空闲时间的百分比
- %steal : 显示了当hypervisor正服务于另外一个虚拟处理器时无意识地等待虚拟CPU所占有的时间百分比。
- %idle : 显示了CPU在I/O没有挂起请求时空闲时间的百分比
第二部分包含了设备利用率报告
- Device : 列出的/dev 目录下的设备/分区名称
- tps : 显示每秒传输给设备的数量。更高的tps意味着处理器更忙。
- Blk_read/s : 显示了每秒从设备上读取的块的数量(KB,MB)
- Blk_wrtn/s : 显示了每秒写入设备上块的数量(KB,MB)
- Blk_read : 显示所有已读取的块
- Blk_wrtn : 显示所有已写入的块
以KB或MB捕捉iostat
默认上,iostat以B为单位衡量I/O系统。为了更便于阅读,我们可以iostat将报告转换成以KB或者MB为单位。只需要加入-k参数来创建以KB为单位,-m参数来创建以MB为单位。
-x参数

rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;wsec/:每秒写入的扇区数。r/s:The number of read requests that were issued to the device per second;w/s:The number of write requests that were issued to the device per second;
await:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。